

提示
精通一个领域
- Chunk it up 切碎知识点
- 庖丁解牛
- 脉络链接
- Deliberate Practicing 刻意练习
- Feedback 反馈
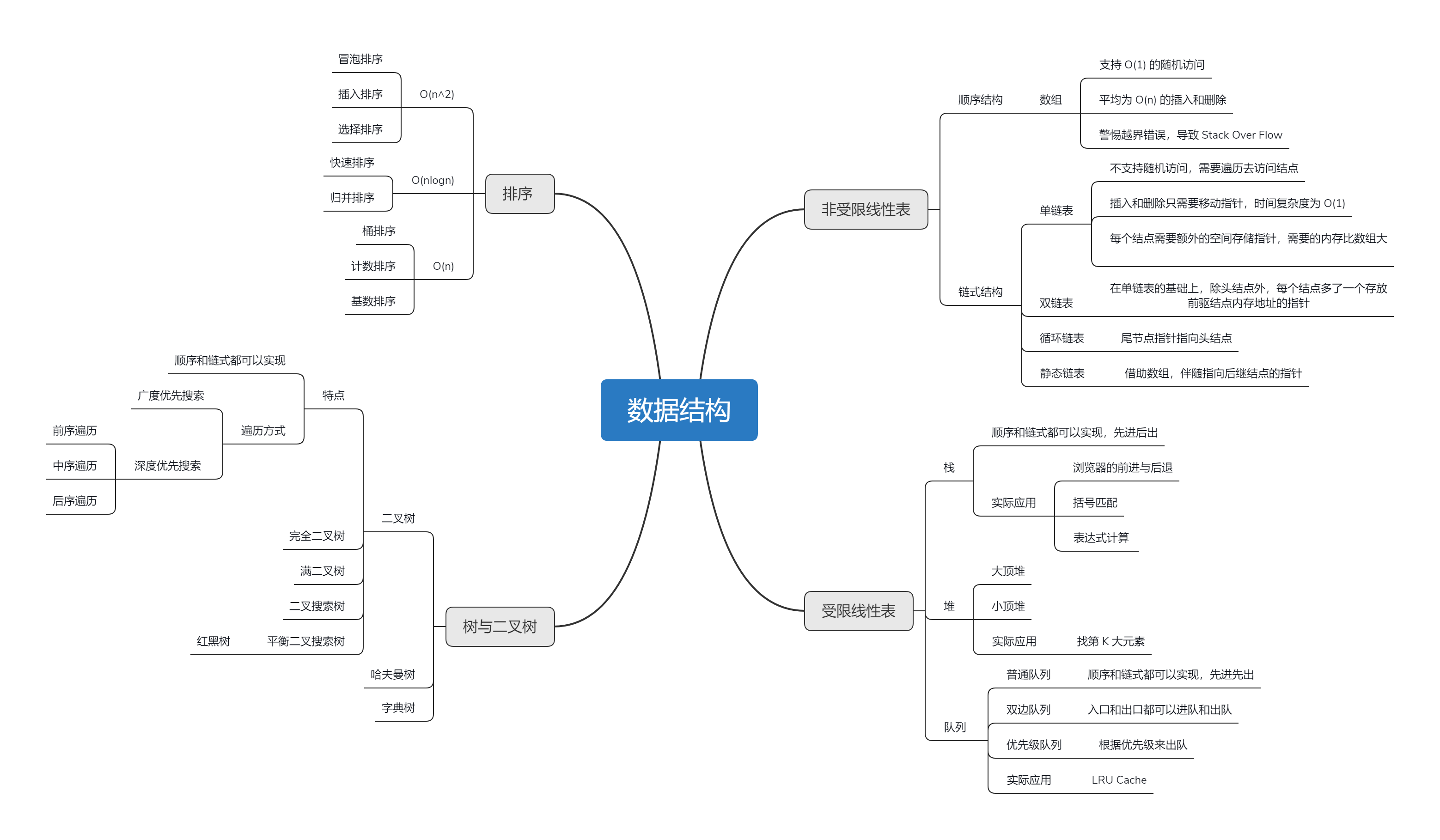
数据结构
-
一维:
- 基础:数组 array (string),链表 linked list
- 高级:栈 stack,队列 queue,双端队列 deque,集合 set,映射 map (hash or map),etc
-
二维:
- 基础:树 tree,图 graph
- 高级:二叉搜索树 binary search tree (red-black tree,AVL),堆 heap,并查集 disjoint set,字典树 Trie,etc
-
特殊:
- 位运算 Bitwise,布隆过滤器 BloomFilter
- LRU Cache
算法
- if-else,switch ——> branch
- for,while loop ——> literation
- 递归 Recursion (Divide & Conquer ,Backtrace)
所有高级算法或数据结构最后都会转换成以上三种
-
搜索 Search:深度优先搜索 Depth first search, 广度优先搜索 Breadth first search,A*,etc
-
动态规划 Dynamic Programming
-
二分查找 Binary Search
-
贪心 Greedy
-
数学 Math,几何 Geometry
职业化运动
-
基本功是区别业余和职业化选手的根本
-
基础动作的分解训练和反复练习 ——> 最大的误区
Deliberate Practicing
-
练习缺陷、弱点地方
Feedback
-
即时反馈
-
主动型反馈(自己去找)
- 高手代码(Github,Leetcode,etc)
- 第一视角直播
-
被动式反馈(高手给你指点)
- code review
切题四件套
- Clarification
- Possible Solutions
- compare (time/space)
- optimal (加强)
- Coding(多写)
- Test cases
小结
- 职业训练:拆分知识点、刻意练习、反馈
- 五步刷题法
- 做算法题最大的误区:只做一遍
训练环境设置、编码技巧和Code Style
- 上国际站看解答
‘’自顶向下‘’的编程方式
时间复杂度和空间复杂度
Big O notation
- O(1):Constant Complexity 常数复杂度
- O(log n):Logarithmic Complexity 对数复杂度
- O(n):Linear Complexity 线性时间复杂度
- O(n^2):N Square Complexity 平方
- O(n^3):N Square Complexity 立方
- O(2^n):Exponential Growth 指数
- O(n!):Factorial 阶乘
注意:只看最高复杂度的运算
O(1)
# 看代码执行了1次
n = 1000
print(n) # 不管n为多少,print只执行一次
# 代码执行了三次,O(3),还是O(1)
m = 1000
print(m)
print(m)
print(m)O(N)
# 代码执行了n次
for i in range(n):
print('执行了:',i)O(N^2)
for i in range(n):
for j in range(m):
print('执行了:',i+j)O(log(n))
# 这个需要重写
for i*i in range(n):
print(i)
O(k^n):
def fib(n):
if n <= 2 :
return n
else:
return fib(n-1) + fib(n-2)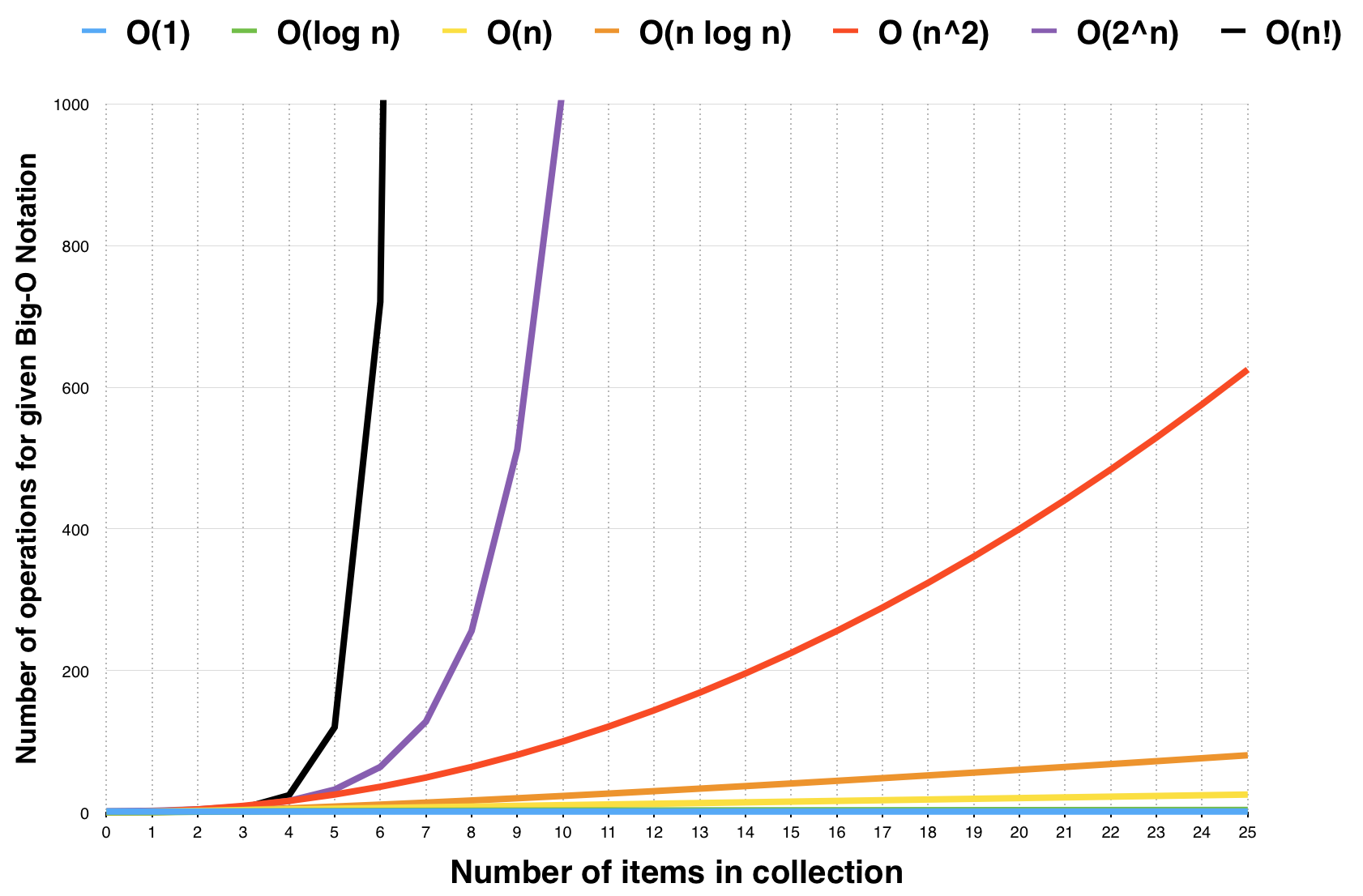
计算:1+2+…+n:
-
方法一:
# O(n) y = 0 for i in range(1,n+1): y += i - 方法二:
# O(1) y = n * (n+1) / 2
更复杂的情况:递归
试着画出递归树(状态树)
Fib:0,1,1,2,3,5,8,13,21,…
-
F(n) = F(n-1) + F(n-2)
-
最简单的写法,直接用递归
def fib(n): if n <= 2: return n return fib(n-1)+fib(n-2)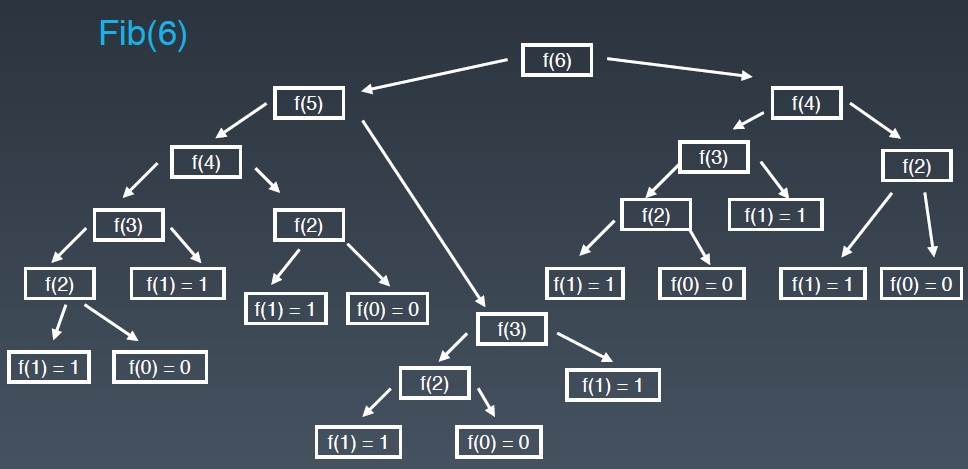
- 两个'灾难':
- 每展开一层,运行的节点数就是上层的两倍,按指数级递增
- 存在重复计算的节点
- 两个'灾难':
Master Theorem
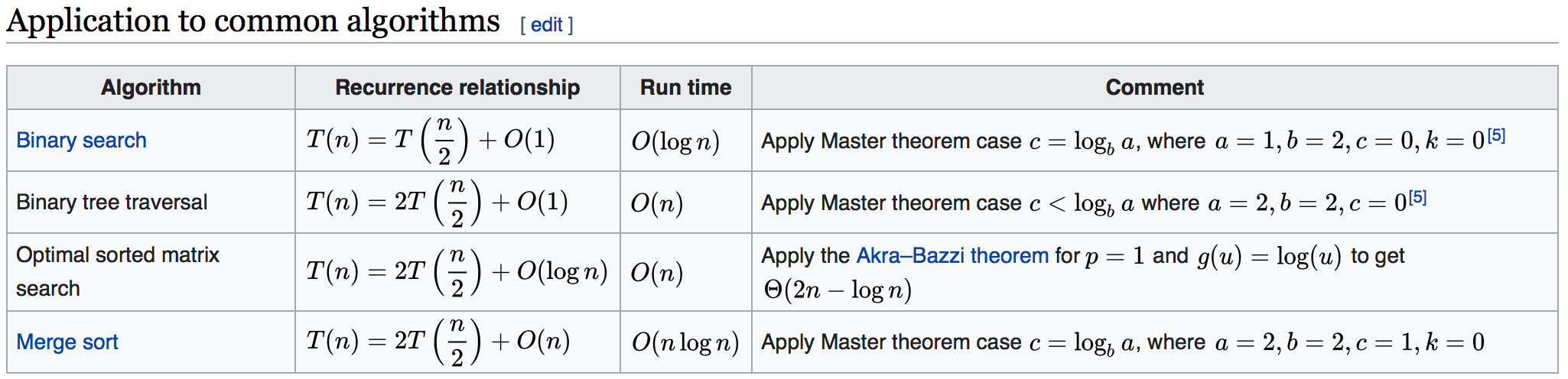
- 一维数组二分查找:每次排除一半,故为O(log n)
- 二叉树的遍历:可以理解成每个节点被访问且仅访问一次,故为O(n)
- 二维矩阵的二分查找:O(n)
- 归并排序:O(n logn)
思考
-
二叉树遍历:前序、中序、后序的时间复杂度是多少?
- O(n)
-
图的遍历:时间复杂度是多少?
- O(n)
-
搜索算法:DFS、BFS的时间复杂度是多少?
- O(n)
1-3中因为每个节点访问且只访问一次
-
二分查找:时间复杂度是多少?
- O(log n)
Array
创建
Java、C++: int a[100]
Python:list=[]
JavaScript:let x=[1,2,3] # 可以放入初始值
高级语言对列表内元素类型无要求。——语言的泛型
结构
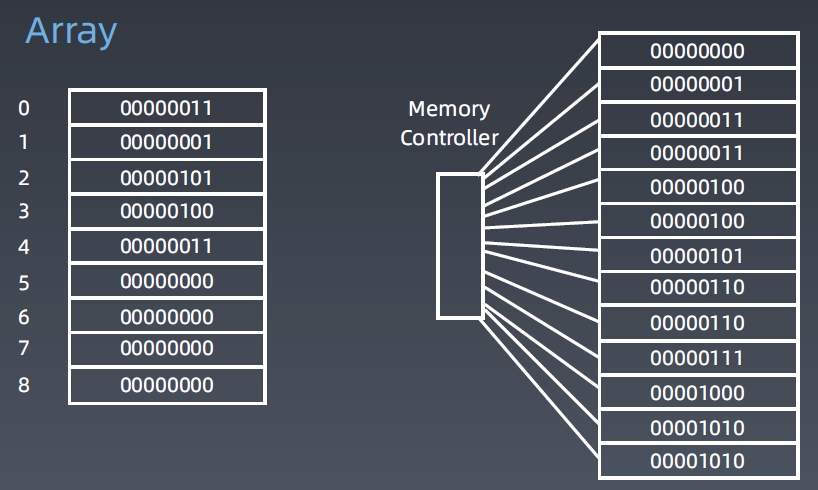
-
可以随机访问任何一个元素,时间为O(1)。
-
插入、删除元素,时间为O(n)。
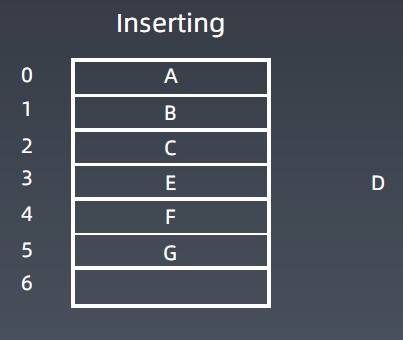
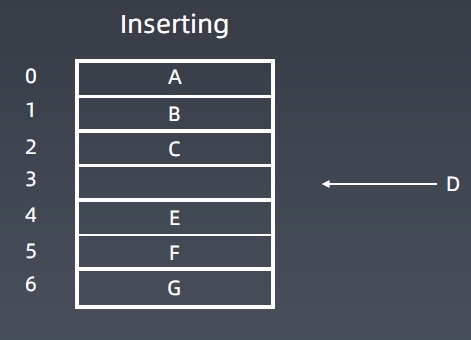
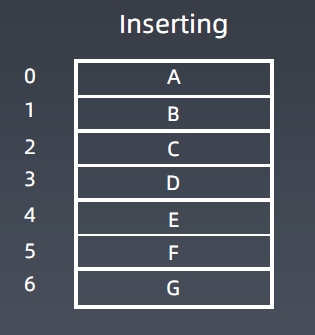
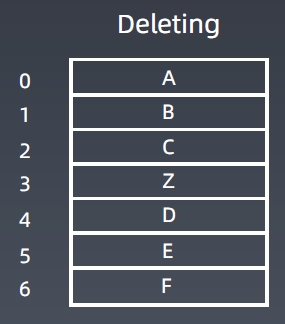
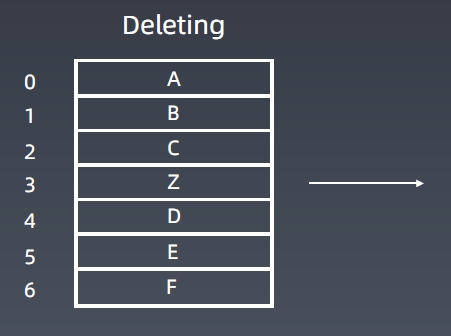
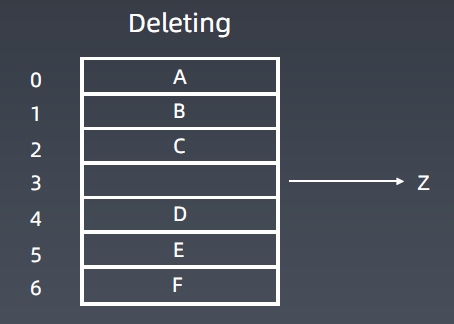

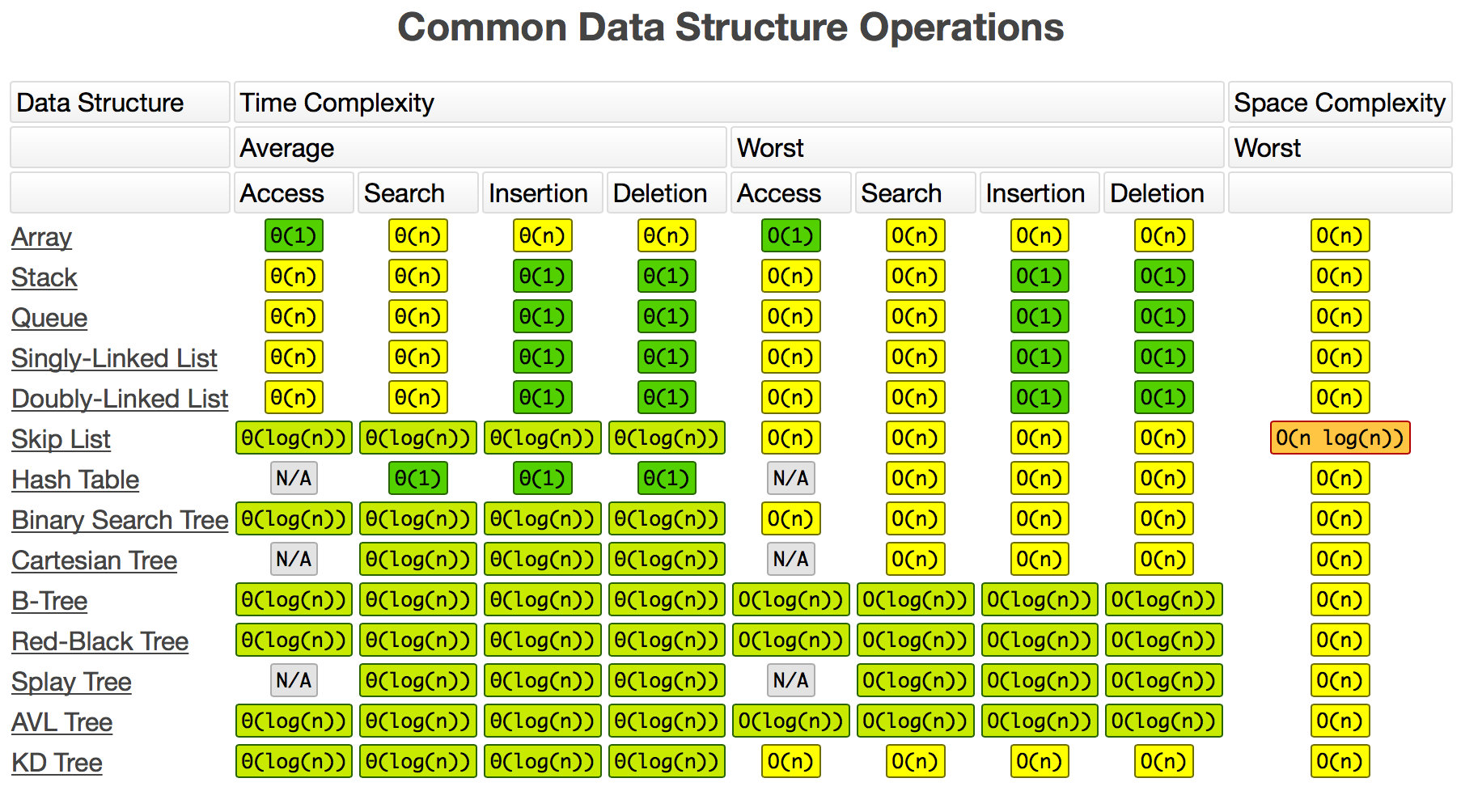
各种操作的时间复杂度
| 操作 | 时间复杂度 |
|---|---|
| prepend | O(1) |
| append | O(1) |
| lookup | O(1) |
| insert | O(n) |
| delete | O(n) |
Linked List
结构
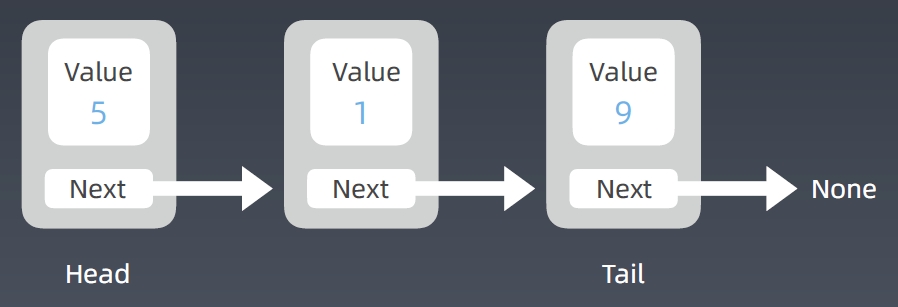
- 只有一个指针,称之为单链表
- 多加一个前项指针,称之为双链表
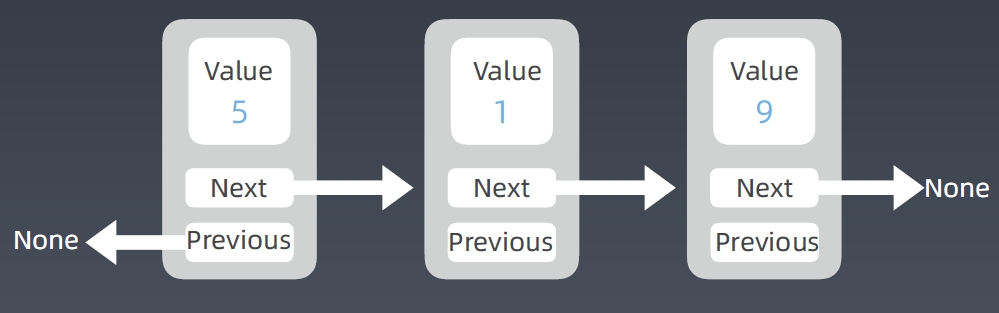
Double Linked List
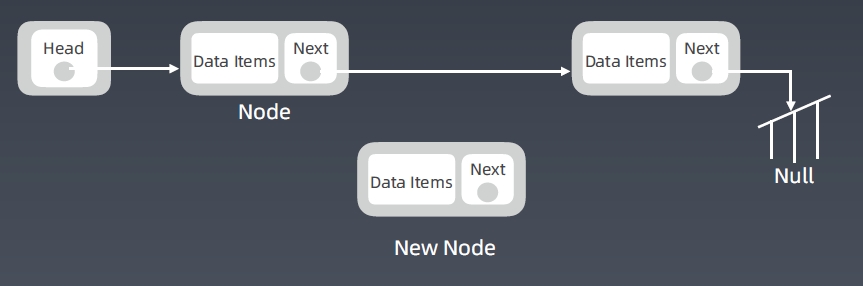
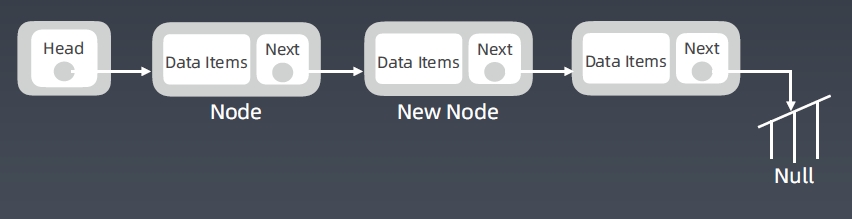
Linked List 增加节点

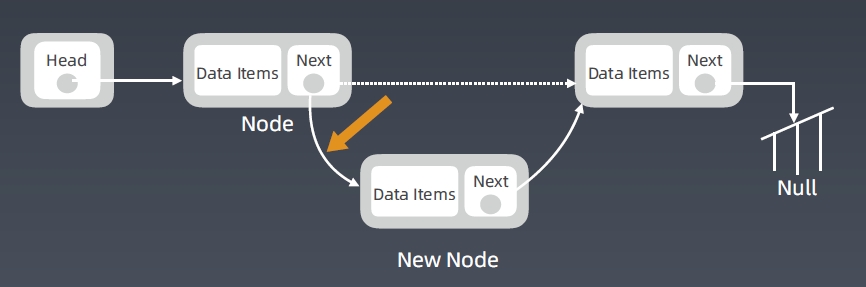
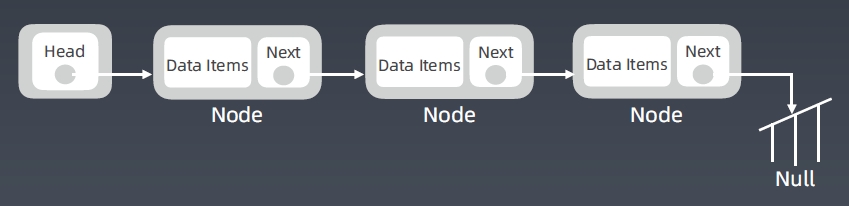
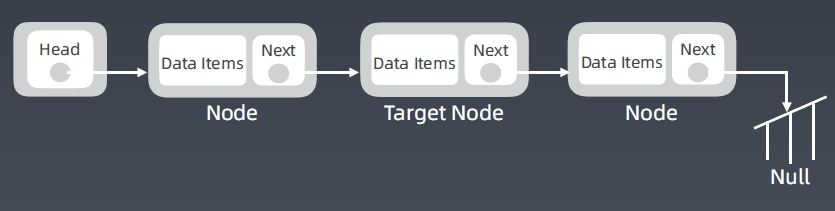
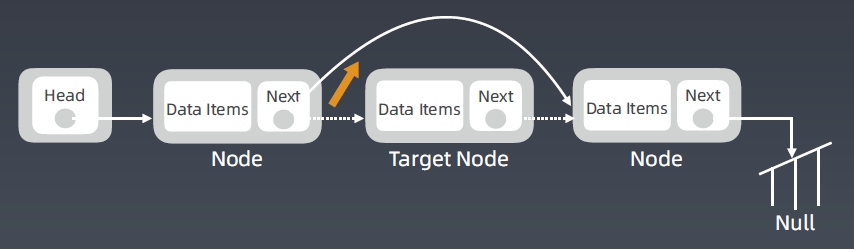
Linked List 删除节点
各种操作的时间复杂度
| 操作 | 时间复杂度 |
|---|---|
| prepend | O(1) |
| append | O(1) |
| lookup | O(n) |
| insert | O(1) |
| delete | O(1) |
链表的优化
核心思想:升维思想,空间换时间
解决方法:增加多级索引,log(2n)个索引
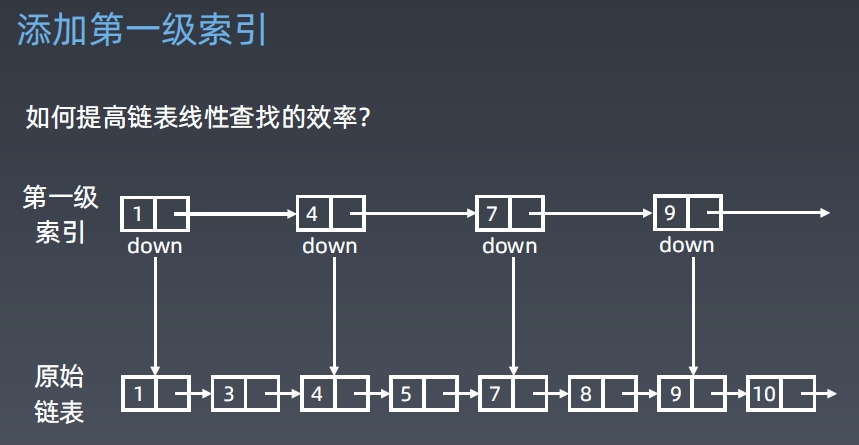
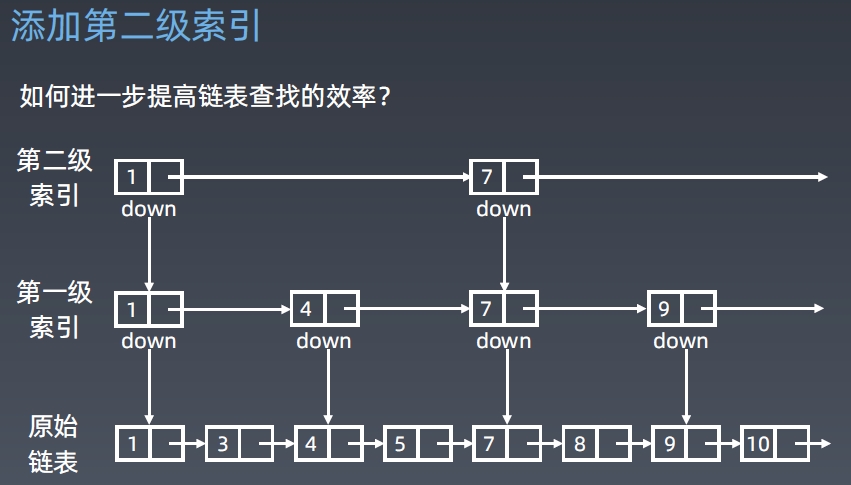
以此类推,增加多级索引。
跳表 Skip List
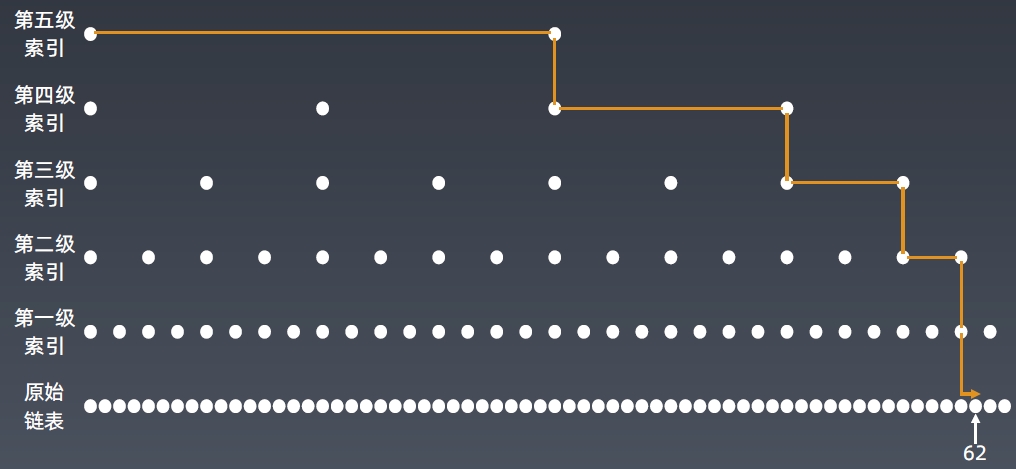
跳表查询的时间复杂度分析
n/2、n/4、n/8、第k级索引结点的个数就是
$$
\frac{n}{2^k}
$$
假设索引有h级,最高级的索引有2个结点:
$$
\frac{n}{2^h}=2
$$
,从而求得
$$
h=\log _2n-1
$$
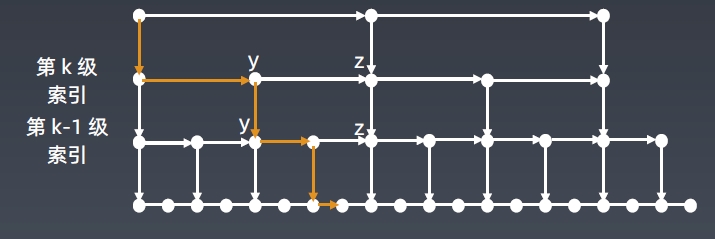
索引高度:log n,每层索引遍历的结点个数:3
在跳表中查询任意数据的时间复杂度是O(log n)
现实中跳表的形态
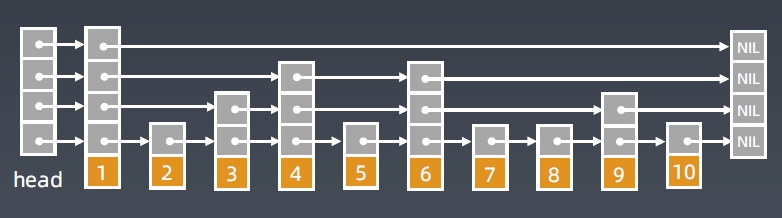
跳表的空间复杂度分析
原始链表大小为n,每2个结点抽1个,每层索引的结点数:
$$
\frac{n}{2},\frac{n}{4},\frac{n}{8},...,8,4,2
$$
原始链表大小为n,每3个结点抽1个,每层索引的结点数:
$$
\frac{n}{3},\frac{n}{9},\frac{n}{27},...,9,3,1
$$
空间复杂度是O(n)
工程中应用
LRU Cache - Linked list
https://www.jianshu.com/p/b1ab4a170c3c
https://leetcode-cn.com/problems/lru-cache
Redis - Skip List
https://redisbook.readthedocs.io/en/latest/internal-datastruct/
skiplist.html
https://www.zhihu.com/question/20202931
小结
• 数组、链表、跳表的原理和实现
• 三者的时间复杂度、空间复杂度
• 工程运用
• 跳表:升维思想 + 空间换时间
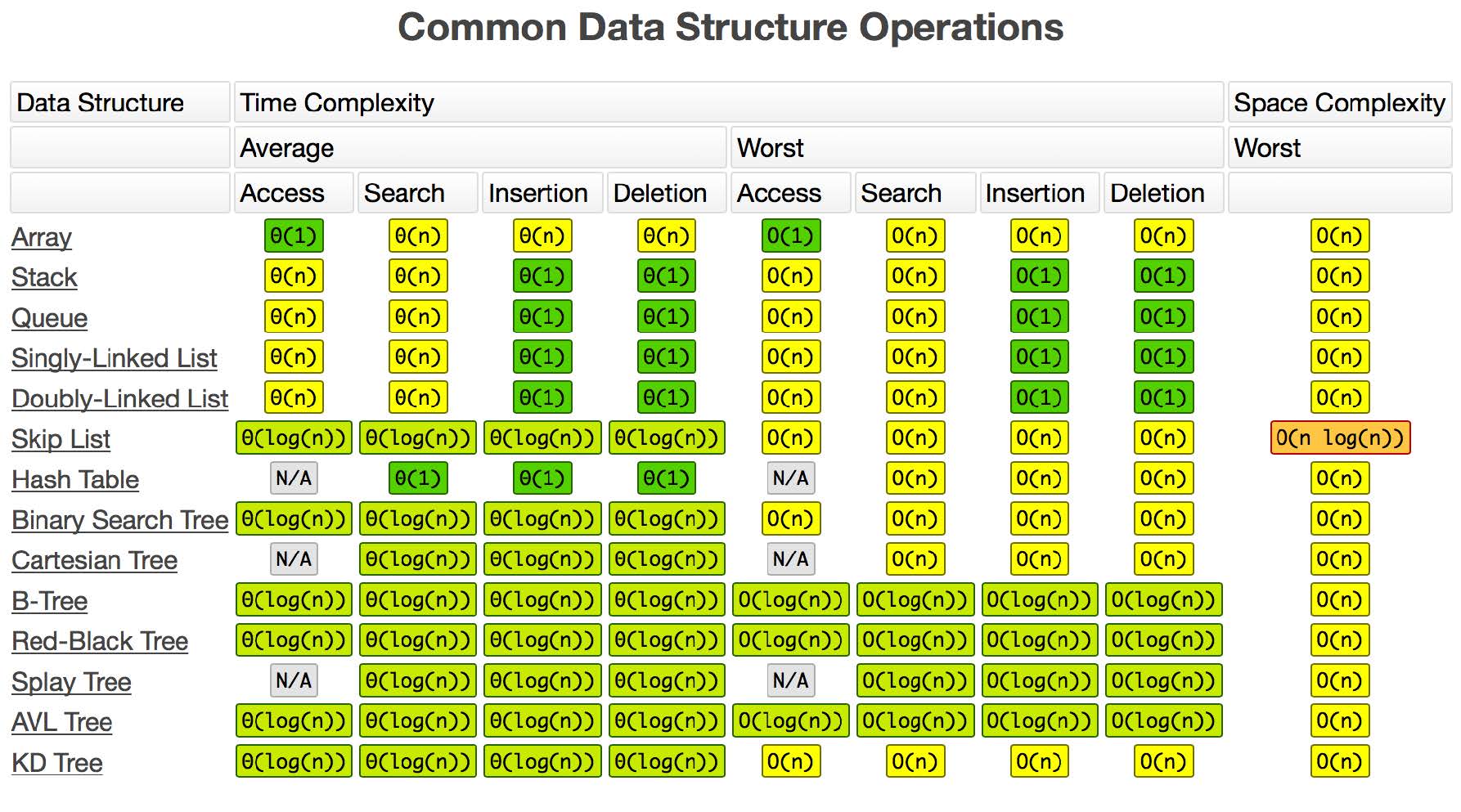
Stack
先入后出(FILO)的容器结构,最近相关性问题(洋葱结构)使用栈解决!
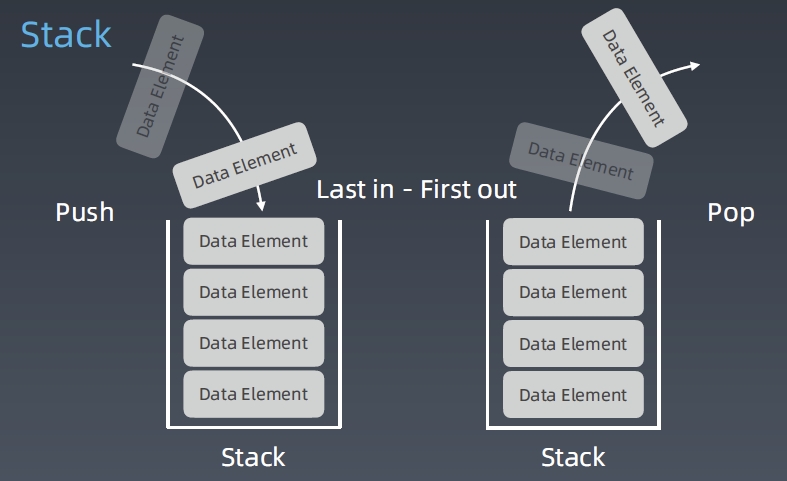
添加、删除皆为$O(1)$,查询为$O(n)$
Queue
先入先出(FIFO)的容器结构
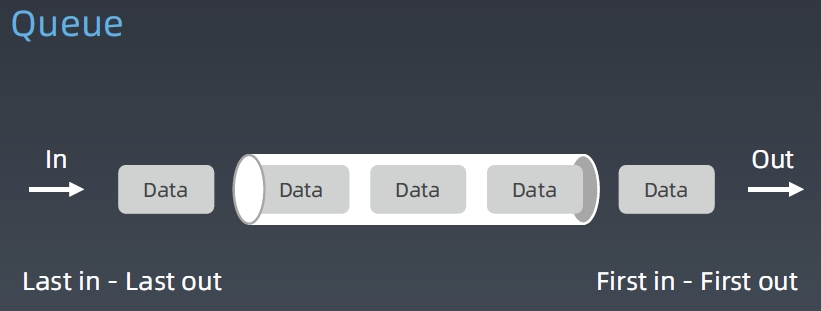
添加、删除皆为$O(1)$,查询为$O(n)$
Deque: Double-End Queue
实战中经常使用的是双端队列
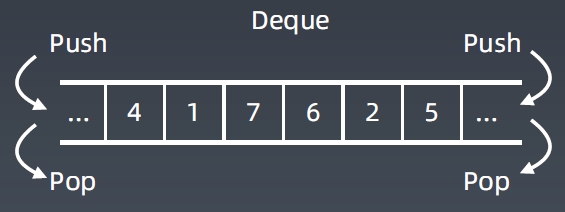
- 简单理解:两端可以进出的 Queue
- 插入和删除都是 $O(1)$ 操作,查询是 $O(n)$
Stack、Queue、Deque 的工程实现
-
是使用一个数组进行模拟
-
如何查询接口信息?如何使用?
以Java为例,在Google中直接搜索"Stack Java12"
-
代码示例
Stackstack = new Stack<>(); stack.push(1); stack.push(2); stack.push(3); stack.push(4); System.out.println(stack); System.out.println(stack.search(4)); stack.pop(); stack.pop(); Integer topElement = stack.peek(); System.out.println(topElement); System.out.println(" 3的位置 " + stack.search(3)); Queuequeue = new LinkedList (); queue.offer("one"); queue.offer("two"); queue.offer("three"); queue.offer("four"); System.out.println(queue); String polledElement = queue.poll(); System.out.println(polledElement); System.out.println(queue); String peekedElement = queue.peek(); System.out.println(peekedElement); System.out.println(queue); while(queue.size() > 0) { System.out.println(queue.poll()); } - Deque
Dequedeque = new LinkedList (); deque.push("a"); deque.push("b"); deque.push("c"); System.out.println(deque); String str = deque.peek(); System.out.println(str); System.out.println(deque); while (deque.size() > 0) { System.out.println(deque.pop()); } System.out.println(deque);
Priority Queue
面试中常考的数据结构
-
插入操作:O(1)
-
取出操作:$O(logN)$ - 按照元素的优先级取出,每次取是取优先级最高的。
-
底层具体实现的数据结构较为多样和复杂:heap、bst、treap
Python相关代码
class Stack:
def __init__(self):
self.items = ['x', 'y']
def push(self, item):
self.items.append(item)
def pop(self):
self.items.pop()
def length(self):
return len(self.items)class Queue:
def __init__(self):
self.queue = []
def enqueue(self, item):
self.queue.append(item)
def dequeue(self):
if len(self.queue) < 1:
return None
return self.queue.pop(0)
def size(self):
return len(self.queue)复杂度分析
小结
- Stack、Queue、Deque 的原理和操作复杂度
- PriorityQueue 的特点和操作复杂度
- 查询 Stack、Queue、Deque、PriorityQueue 的系统接口的方法
Hash table
- 哈希表(Hash table),也叫散列表,是根据关键码值(Keyvalue)而直接进行访问的数据结构。
- 它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。
- 这个映射函数叫作散列函数(Hash Function),存放记录的数组叫作哈希表(或散列表)。
工程实践
- 电话号码簿
- 用户信息表
- 缓存(LRU Cache)
- 键值对存储(Redis)
Hash Function
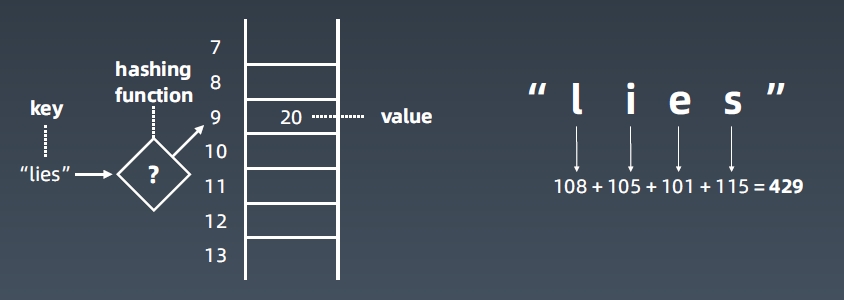
好的哈希函数可以让数值尽量分散,不会出现哈希碰撞
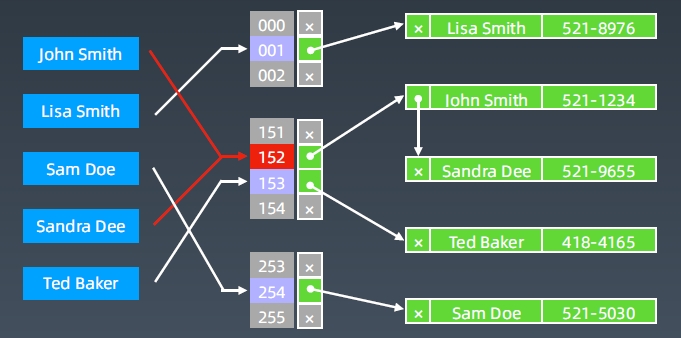
Hash Collisions

-
发生哈希碰撞解决办法就是在碰撞的地方存一个链表——拉链式解决冲突法
-
Hash表查询O(1),最坏发生碰撞,退化为O(n)
复杂度分析
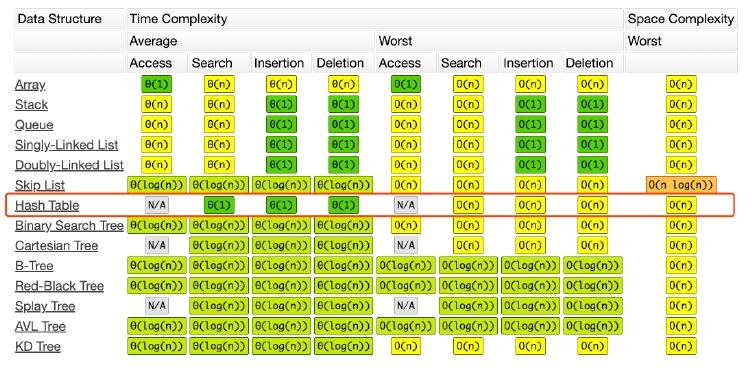
Map、Set
- Map : key-value对,key不重复
- Set : 不重复元素的集合

list_x = [1,2,3,4]
map_x = {
'jack':100,
'张三':80,
'selina':90,
...
}
set_x = {'jack','selina','Andy'}
set_y = set(['jack','selina','jack'])-
Java set classes:
==TreeSet, HashSet,==
ConcurrentSkipListSet, CopyOnWriteArraySet, EnumSet, JobState
Reasons, LinkedHashSethttps://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/util/Set.html
-
Java map classes:
==HashMap, Hashtable, ConcurrentHashMap==
https://docs.oracle.com/en/java/javase/12/docs/api/java.base/java/util/Map.html
要会去查看Python实现的源代码
复杂度分析
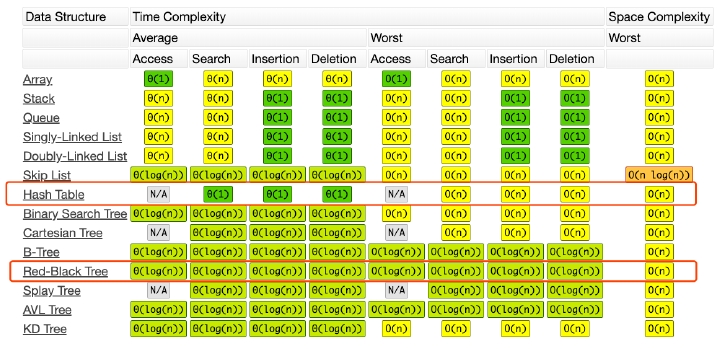
养成总结代码的习惯
链表等一维结构
单链表 Linked List
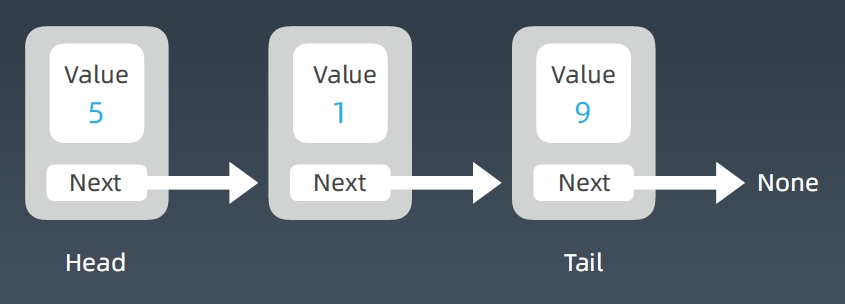
提高一维结构的性能:升维
树 Tree
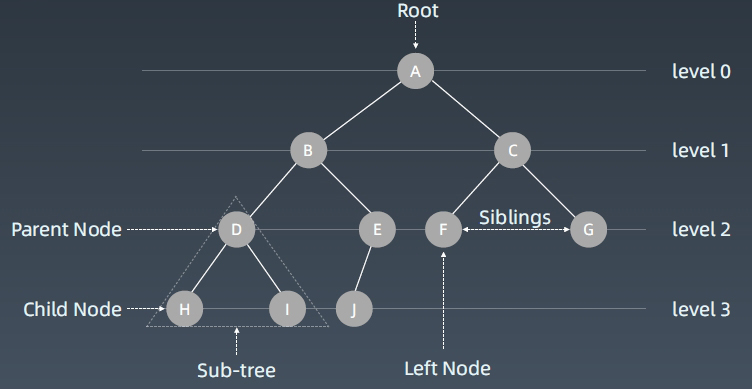
树和图最大的差别就是看有没有环
图 Graph
Linked List 是特殊化的 Tree
Tree 是特殊化的 Graph
二叉树 Binary Tree——最常见的树结构
一个节点只有两个子节点
树的节点定义示意代码:
class TreeNode:
def __init__(self,val):
self.val = val
self.left,self.right = None,None
struct TreeNode {
int val;
TreeNode *left;
TreeNode *right;
TreeNode(int x) : val(x), left(NULL), right(NULL) {}
}public class TreeNode {
public int val;
public TreeNode left, right;
public TreeNode(int val) {
this.val = val;
this.left = null;
this.right = null;
}
}二叉树遍历 Pre-order/In-order/Post-order
- 前序 (Pre-order):根-左-右
- 中序 (In-order):左-根-右
- 后序(Post-order):左右根
三种遍历的命名在于根节点访问顺序的不同。树的遍历方式基于递归,因为树的构造决定了它没法有效的进行循环,递归无所谓效率好坏,而在于是否算法合理。
示例代码:
def preorder(self,root):
if root:
self.traverse_path.append(root.val)
self.preorder(root.left)
self.preorder(root.right)
def inorer(self,root):
if root:
self.inorder(root.left)
self.traverse_path.append(root.val)
self.inorder(root.right)
def postorder(self,root):
if root:
self.postorder(root.left)
self.postorder(root.left)
self.traverse_path.append(root.val)二叉搜索树 Binary Search Tree
二叉搜索树,也称二叉搜索树、有序二叉树(Ordered Binary Tree)、排序二叉树(Sorted Binary Tree),是指一棵空树或者具有下列性质的二叉树:
-
左子树上所有结点的值均小于它的根结点的值;
-
右子树上所有结点的值均大于它的根结点的值;
-
以此类推:左、右子树也分别为二叉查找树。 (这就是 重复性!)
中序遍历:升序排列
二叉搜索树常见操作
相比于单链表的O(n)的操作,二叉搜索树的操作降到了O(log(n))
- 查询
- 插入新结点(创建)
- 删除:
- 删除叶结点很简单;
- 删除某个根节点:找到它周围最接近它的值的节点替换掉它,往往是找到刚刚大于这个根节点的节点值
复杂度分析
思考
树的面试题解法一般都是递归,为什么?
结点的定义就是以递归方式进行;
重复性(自相似性)
二叉搜索树:左子树小于根节点,右子树大于根节点,且左右子树具有相同特征
为什么树的面试题解法一般都是递归?
- 节点的定义
- 重复性(自相似性)
二叉树的前序遍历示例代码:
def preorder(self, root):
if root:
self.traverse_path.append(root.val)
self.preorder(root.left)
self.preorder(root.right)
def inorder(self, root):
if root:
self.inorder(root.left)
self.traverse_path.append(root.val)
self.inorder(root.right)
def postorder(self, root):
if root:
self.postorder(root.left)
self.postorder(root.right)
self.traverse_path.append(root.val)递归-Recursion
- 递归 - 循环
- 通过函数体来进行的循环
- 从前有个山
- 山里有个庙
- 庙里有个和尚讲故事
- 返回1

盗梦空间
- 向下进入到不同梦境中;向上又回到原来一层——归去来兮
- 通过声音同步回到上一层
- 每一层的环境和周围的人都是一份拷贝、主角等几个人(想当于函数里面的参数)穿越不同层级的梦境(发生和携带变化)
简单的递归例子:计算 n!
$n!= 1 2 3 … n$
def Factorial(n):
if n <= 1:
return 1
return n * Factorial(n — 1)
递归的Python模版
def recursion(level, param1, param2, ...):
# recursion terminator 递归终止条件,否则会无限递归造成死循环
if level > MAX_LEVEL:
process_result
return
# process logic in current level 处理当前层逻辑
process(level, data...)
# drill down 下探到下一层
self.recursion(level + 1, p1, ...)
# reverse the current level status if needed 清理当前层递归的Java模版
public void recur(int level, int param) {
// terminator
if (level > MAX_LEVEL) {
// process result
return;
}
// process current logic
process(level, param);
// drill down
recur( level: level + 1, newParam);
// restore current status
}思维要点
- 不要人肉进行递归(最大误区)
- 找到最近最简方法,将其拆解成可重复解决的问题(重复子问题)
- 数学归纳法思维
分治和回溯的本质上是递归。
碰到一个题目找最近重复性:递归;或者找最优重复性:动态规划。
递归状态树
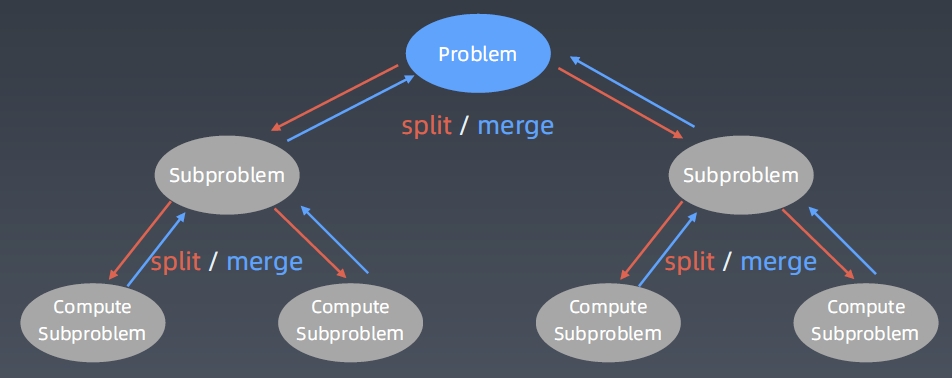
本质:找重复性和分解问题,最后再组合每个子问题的结果。
分治 Divide & Conquer
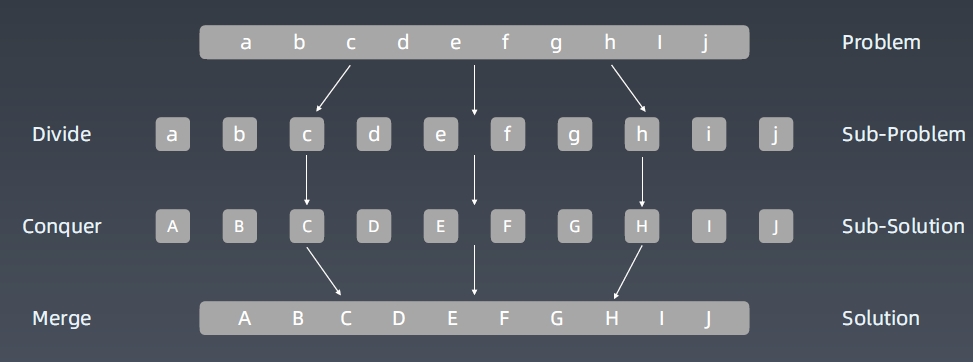
分治代码模版
和递归的代码模版一模一样
def divide_conquer(problem, param1, param2, ...):
# recursion terminator
if problem is None: # 对于分治来说一般是到达了叶子节点
print_result
return
# prepare data
data = prepare_data(problem)
subproblems = split_problem(problem, data)
# conquer subproblems
subresult1 = self.divide_conquer(subproblems[0], p1, ...)
subresult2 = self.divide_conquer(subproblems[1], p1, ...)
subresult3 = self.divide_conquer(subproblems[2], p1, ...)
...
# process and generate the final result
result = process_result(subresult1, subresult2, subresult3, …)
# revert the current level states回溯 Backtracking
回溯法采用试错的思想,它尝试分步的去解决一个问题。在分步解决问题的过程中,当它通过尝试发现现有的分步答案不能得到有效的正确的解答的时候,它将取消上一步甚至是上几步的计算,再通过其它的可能的分步解答再次尝试寻找问题的答案。
回溯法通常用最简单的递归方法来实现,在反复重复上述的步骤后可能出现两种情况:
- 找到一个可能存在的正确的答案;
- 在尝试了所有可能的分步方法后宣告该问题没有答案。
在最坏的情况下,回溯法会导致一次复杂度为指数时间的计算。
归去来兮
遍历搜索
在树(图/状态集)中寻找特定节点,一般都是从根开始。
Python中树的节点定义:
class TreeNode:
def __init__(self,val):
self.val = val
self.left,self.right = None,None搜索-遍历
- 每个节点都要访问
- 每个节点仅仅要访问一次——主要是为了效率
- 对于节点的访问顺序不限
- 深度优先:depth first search
- 广度优先:breadth first search
- 优先级优先
DFS算法——通过递归、栈实现
遍历顺序
树:
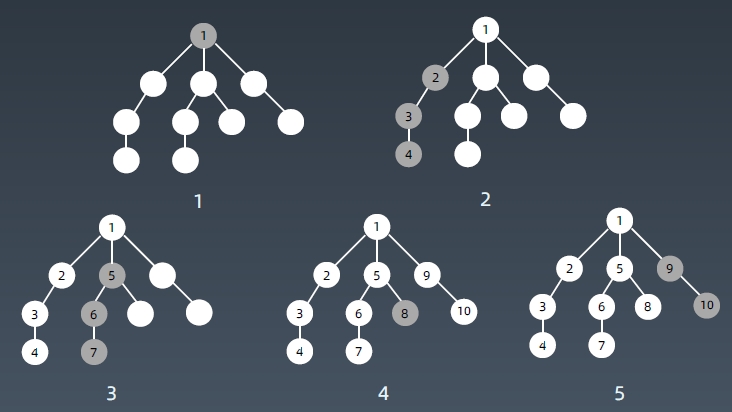
图:
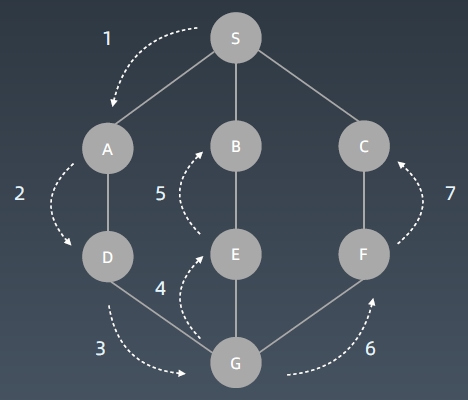
DFS代码模版:
visited = set()
def dfs(node):
if node in visited:
# already visited
return
visited.add(node) # 不要忘了加进去
# process current node
# ...# logic here
dfs(node.left)
dfs(node.right)DFS递归方式代码模版:
visited = set()
def dfs(node, visited):
if node in visited: # terminator
# already visited
return
visited.add(node)
# process current node here.
...
for next_node in node.children():
if not next_node in visited:
dfs(next_node, visited) # 递归调用的好处是不用等循环跑完,就已经进入下一层了栈实现方式模版:
def DFS(self, tree):
if tree.root is None:
return []
visited, stack = [], [tree.root]
while stack:
node = stack.pop()
visited.add(node)
process (node)
nodes = generate_related_nodes(node)
stack.push(nodes)
# other processing work
...BFS算法-通过队列实现
遍历顺序
树的遍历(类似于水波纹扩散):
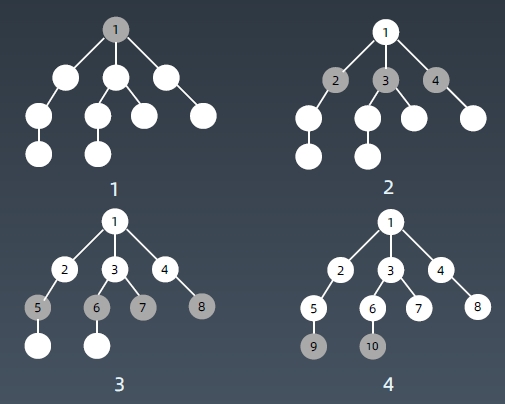
BFS与DFS遍历顺序比较:
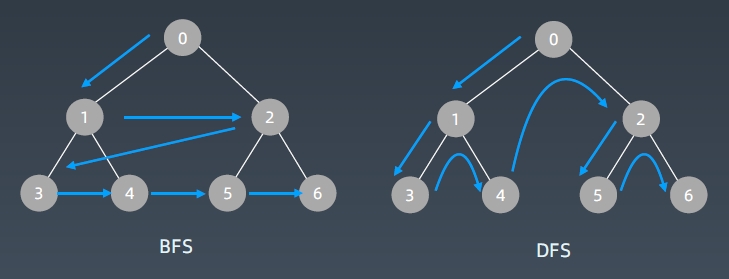
BFS队列实现代码:
def BFS(graph, start, end):
queue = []
queue.append([start])
visited.add(start)
while queue:
node = queue.pop()
visited.add(node)
process(node)
nodes = generate_related_nodes(node)
queue.push(nodes)
# other processing work
...贪心算法 Greedy
贪心算法是一种在每一步选择中都采取在当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。
- 贪心:当下做局部最优判断
- 回溯:能够回退
- 动态规划:最有判断+回退 动态规划-维基百科
贪心法可以解决一些最优化问题,如:求图中的最小生成树、求哈夫曼编码等。然而对于工程和生活中的问题,贪心法一般不能得到我们所要求的答案。
一旦一个问题可以通过贪心法来解决,那么贪心法一般是解决这个问题的最好办法。由于贪心法的高效性以及其所求得的答案比较接近最优结果,贪心法也可以用作辅助算法或者直接解决一些要求结果不特别精确的问题。
贪心算法难就难在怎么证明使用贪心法。
实战题目
Coin Change 特别版本:
322. 零钱兑换
讲解:
当硬币可选集合固定:Coins = [20, 10, 5, 1],求最少可以几个硬币拼出总数。 比如 total = 36
贪心算法 Greedy
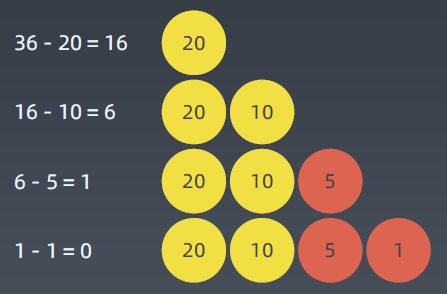
为什么可以使用贪心法,因为在这里[20,10,5,1]中,前面的硬币都是后面硬币的倍数,所以使用贪心法每次用最大的即可。
贪心法的反例:
非整除关系的硬币,可选集合:Coins = [10, 9, 1]

求拼出总数为 18 最少需要几个硬币?
最简单的组合就是两个9:

但如果使用贪心算法:
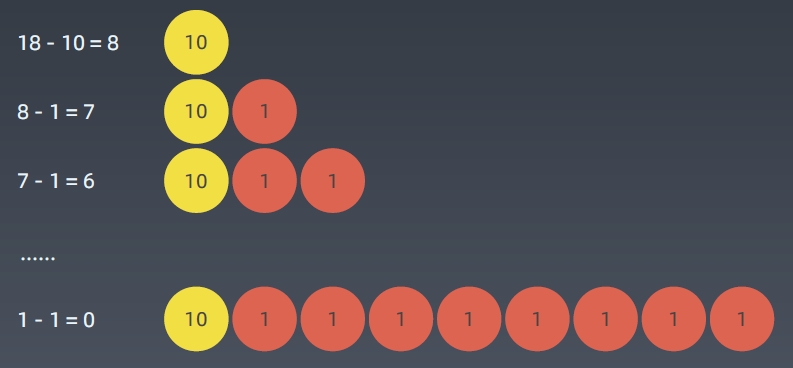
适用贪心算法的场景
简单地说,问题能够分解成子问题来解决,子问题的最优解能够递推到最终问题的最优解。这种子问题最优解称为最优子结构。
贪心算法与动态规划的不同在于它对每个子问题的解决方案都做出选择,不能回退。动态规划则会保存以前的运算结果,并根据以前的结果对当前进行选择,有回退功能。

发表回复