

[TOC]
1.无重复字符的最长子串
关键字:哈希表、双指针、字符串、Sliding Window
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例 1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例 2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例 3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。解答
传统的解法是暴力破解,先罗列出这个字符串的所有子串然后依次判断这些子串中是否含有相同字符,这样做太慢了
下面介绍滑动窗口求最大子串:
“滑动窗口”这个概念在计算机算法中非常常见。该算法可以把嵌套的循环转化为单循环从而降低时间复杂度。它在很多不同的领域都有应用:
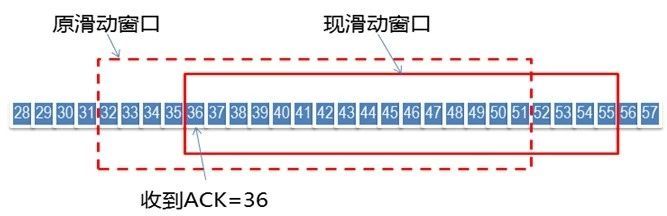
1.TCP协议的滑动窗口进行流量控制
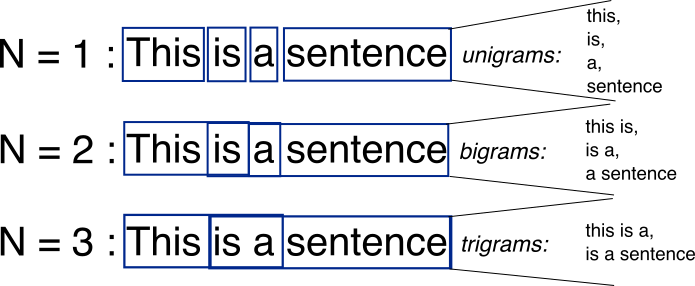
2.NLP(自然语言处理)中的 N-gram
3.图像处理中的物体识别

下面开始使用滑动窗口求解最大子串,例如题目中的‘abcabcbb’例子:
开始的时候,begin和end都指向0的位置即‘a’,然后end不断后移(窗口变宽),当遇到第二个‘a’时(遇见重复字符)就得到一个子串,其长度就是end和begin位置的差。
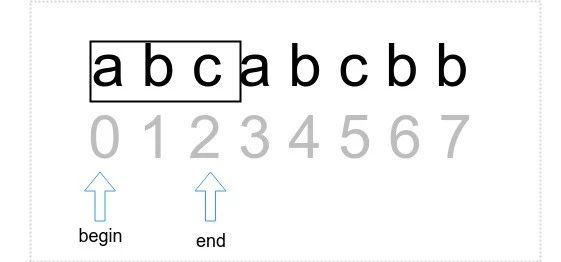
如何判断是否遇到了重复字符‘a’呢?需要一个字典作为辅助数据结构,把end从头开始遇到的每个字符及其索引位置都放到字典里面,end每次移动到新字符就查一下字典即可。
通过字典,我们遇到第二个‘a’时就可以找到存在字典里面的第一个‘a’的位置。为了继续寻找无重复子串,begin就要指向第一个‘a’后面一个的位置即‘b’。然后end继续后移到‘b’,有发现它与前面的‘b’重复,计算子串长度赋值给最大长度(需要比较),同时begin要移动第一个‘b’后面的位置即‘c’。
这样依次移动end到字符串末尾就可以找到最长的子串,“子串窗口”也就从头移到了末尾。而只需要end从头到尾的一次循环即可。
class Solution(object):
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
maxlen = 0
memo = dict()
begin, end = 0, 0
n = len(s)
while end < n:
last = memo.get(s[end])
memo[s[end]] = end
if last is not None:
maxlen = max(maxlen, end-begin)
begin = max(begin, last + 1)
end += 1
maxlen = max(maxlen, end-begin)
return maxlen或者:
def lengthOfLongestSubstring(self, s):
"""
:type s: str
:rtype: int
"""
ans = 0
start = 0
end = 0
StrSet = set()
while start < len(s) and end < len(s):
StrLen = len(StrSet)
StrSet.add(s[end])
if not StrLen == len(StrSet):
end += 1
ans = max(ans, end - start)
else:
StrSet.remove(s[start])
start += 1
return ans2.最长公共前缀
关键字:
编写一个函数来查找字符串数组中的最长公共前缀。
如果不存在公共前缀,返回空字符串 ""。
示例 1:
输入: ["flower","flow","flight"]
输出: "fl"示例 2:
输入: ["dog","racecar","car"]
输出: ""
解释: 输入不存在公共前缀。说明:
所有输入只包含小写字母 a-z 。
解答
取不同字符串中同一位置的字符,查看是否相同。
class Solution(object):
def longestCommonPrefix(self, strs):
""" :type strs: List[str] :rtype: str """
res ="" #创建一个空字符串
if len(strs)==0:
return res
temp = strs[0]
for str in strs:
if len(temp) > len(str):
temp = str #找出最短的字符串作为模版
for i in range(0,len(temp)):
for j in range(0,len(strs)):
if strs[j][i]!=temp[i]:
return res;
res = res + temp[i]
return res;其他题解这里
思路:
思路 1:
Python 特性,取每一个单词的同一位置的字母,看是否相同。思路 2:
取一个单词 s,和后面单词比较,看 s 与每个单词相同的最长前缀是多少!遍历所有单词思路 3:
按字典排序数组,比较第一个,和最后一个单词,有多少前缀相同。代码:
思路一:class Solution: def longestCommonPrefix(self, strs): """ :type strs: List[str] :rtype: str """ res = "" for tmp in zip(*strs): tmp_set = set(tmp) if len(tmp_set) == 1: res += tmp[0] else: break return res思路二: PythonJava class Solution: def longestCommonPrefix(self, s: List[str]) -> str: if not s: return "" res = s[0] i = 1 while i < len(s): while s[i].find(res) != 0: res = res[0:len(res)-1] i += 1 return res思路三: PythonJava class Solution: def longestCommonPrefix(self, s: List[str]) -> str: if not s: return "" s.sort() n = len(s) a = s[0] b = s[n-1] res = "" for i in range(len(a)): if i < len(b) and a[i] == b[i]: res += a[i] else: break return res作者:powcai
链接:https://leetcode-cn.com/problems/two-sum/solution/duo-chong-si-lu-qiu-jie-by-powcai-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。解析
class Solution: def longestCommonPrefix(self, strs: List[str]) -> str: r = [len(set(c)) == 1 for c in zip(*strs)] + [0] return strs[0][:r.index(0)] if strs else ''利用好 zip 和 set
【第一行】每次都取各个字符串的同一列字符,放进 set,set 中不会储存重复元素,所以长度为1代表各个字符都是相同的,此时 == 会让它变成 True
【第二行】index 搜索第一个 0 的位置,0 与 False 在值上是等价的,相当于搜索第一个 False 的位置也就是公共前缀的长度
细节补充
zip(*str) 将 str 中所有字符串并列到迭代器中,逐次并列返回 str 中所有字符串的第 1、2、3、…… 个字符
第一行代码末尾添加了一个 [0] 是为了防止 index 函数搜索不到 0 时报错作者:QQqun902025048
链接:https://leetcode-cn.com/problems/two-sum/solution/2-xing-python-by-knifezhu-2/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3.字符串的排列
关键字:
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。
换句话说,第一个字符串的排列之一是第二个字符串的子串。
示例1:
输入: s1 = "ab" s2 = "eidbaooo"
输出: True
解释: s2 包含 s1 的排列之一 ("ba").
示例2:
输入: s1= "ab" s2 = "eidboaoo"
输出: False
注意:
- 输入的字符串只包含小写字母
- 两个字符串的长度都在 [1, 10,000] 之间
解答
from collections import Counter
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
start = 0
end = 0
need_win = Counter(s1)
lookup = Counter()
count = 0
while end < len(s2):
if s2[end] not in need_win.keys():
lookup.clear()
count = 0
start = end + 1
else:
lookup[s2[end]] += 1
count += 1
end = end + 1
while count == len(s1):
while all(map(lambda x:lookup[x] >= need_win[x], need_win.keys())):
if end - start == len(s1):
return True
break
lookup[s2[start]] -= 1
start = start + 1
count -= 1
return False
4.字符串相乘
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
输入: num1 = "2", num2 = "3"
输出: "6"
示例 2:
输入: num1 = "123", num2 = "456"
输出: "56088"
说明:
num1和num2的长度小于110。num1和num2只包含数字0-9。num1和num2均不以零开头,除非是数字 0 本身。- 不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。
解答
前言
没有做过上一题的朋友建议先把 上一题 415 做掉,本题是上一题的升级版,区别在于 415 是求两个字符串的和,而43是求两个字符串的乘积。
竖式乘法
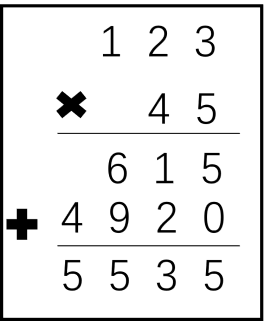
我们先来简单回顾一下小学老师教过的列竖式求乘法的过程:
如下图所示,两个数M和N相乘的结果可以由 M 乘上 N 的每一位数的和得到。
举例 123 45 = 123 5 + 123 *40 = 615 + 4920 = 5535
本题分析
字符串的乘法也可以由列竖式计算的方法得到:让num1 依次乘上 num2 的每一位的和
把第一步里得到的所有和累加在一起,就可以得到 num1 * num2 的结果。
有了上面的分析,可以得到下面的主函数:Python
class Solution(object): def multiply(self, num1, num2): """ :type num1: str :type num2: str :rtype: str """ if num1 == "0" or num2 == "0": #处理特殊情况 return "0" l1, l2 = len(num1), len(num2) if l1 < l2: num1, num2 = num2, num1 #保障num1始终比num2长, 个人习惯 l1, l2 = l2, l1 num2 = num2[::-1] #注意要倒过来乘,方便进位 res = "0" for i, digit in enumerate(num2): tmp = self.StringMultiplyDigit(num1, int(digit)) + "0" * i #计算num1和num2的当前位的乘积 res = self.StringPlusString(res, tmp) #计算res和tmp的和 return res搭好了骨架之后,接下来就是实现 辅助函数 的功能, 辅助函数有三个:
第一个函数是为了计算一个字符串和一个整数的乘积:
核心思路 是:
开一个数组 res, res[i] = int(string[i]) * n
乘完之后再调用第二个辅助函数处理 res 里的进位
最后把 res 转成字符串返回
Pythondef StringMultiplyDigit(self,string, n): #这个函数的功能是:计算一个字符串和一个整数的乘积,返回字符串 #举例:输入为 "123", 3, 返回"369" s = string[::-1] res = [] for i, char in enumerate(s): num = int(char) res.append(num * n) res = self.CarrySolver(res) res = res[::-1] return "".join(str(x) for x in res)第二个函数为了处理乘法结果里的进位:
思路:
把每一位上超过 10 的部分都向后进位,
注意处理最后一位进位时数组需要 append 一下,否则会 下标越界 。
Python
def CarrySolver(self, nums): #这个函数的功能是:将输入的数组中的每一位处理好进位 #举例:输入[15, 27, 12], 返回[5, 8, 4, 1] i = 0 while i < len(nums): if nums[i] >= 10: carrier = nums[i] // 10 if i == len(nums) - 1: nums.append(carrier) else: nums[i + 1] += carrier nums[i] %= 10 i += 1第三个函数为了把两个字符串加在一起:
思路:跟第一个辅助函数类似,但更简单,
直接每一位加在一起然后再调用第二个辅助函数处理进位。
PS:第415题 就是要写这个函数
Python
def StringPlusString(self, s1, s2): #这个函数的功能是:计算两个字符串的和。 #举例:输入为“123”, “456”, 返回为"579" #PS:LeetCode415题就是要写这个函数 l1, l2 = len(s1), len(s2) if l1 < l2: s1, s2 = s2, s1 l1, l2 = l2, l1 s1 = [int(x) for x in s1] s2 = [int(x) for x in s2] s1, s2 = s1[::-1], s2[::-1] for i, digit in enumerate(s2): s1[i] += s2[i] s1 = self.CarrySolver(s1) s1 = s1[::-1] return "".join(str(x) for x in s1)所有代码
Pythonclass Solution(object): def multiply(self, num1, num2): """ :type num1: str :type num2: str :rtype: str """ if num1 == "0" or num2 == "0": #处理特殊情况 return "0" l1, l2 = len(num1), len(num2) if l1 < l2: num1, num2 = num2, num1 #保障num1始终比num2大 l1, l2 = l2, l1 num2 = num2[::-1] res = "0" for i, digit in enumerate(num2): tmp = self.StringMultiplyDigit(num1, int(digit)) + "0" * i #计算num1和num2的当前位的乘积 res = self.StringPlusString(res, tmp) #计算res和tmp的和 return res def StringMultiplyDigit(self,string, n): #这个函数的功能是:计算一个字符串和一个整数的乘积,返回字符串 #举例:输入为 "123", 3, 返回"369" s = string[::-1] res = [] for i, char in enumerate(s): num = int(char) res.append(num * n) res = self.CarrySolver(res) res = res[::-1] return "".join(str(x) for x in res) def CarrySolver(self, nums): #这个函数的功能是:将输入的数组中的每一位处理好进位 #举例:输入[15, 27, 12], 返回[5, 8, 4, 1] i = 0 while i < len(nums): if nums[i] >= 10: carrier = nums[i] // 10 if i == len(nums) - 1: nums.append(carrier) else: nums[i + 1] += carrier nums[i] %= 10 i += 1 return nums def StringPlusString(self, s1, s2): #这个函数的功能是:计算两个字符串的和。 #举例:输入为“123”, “456”, 返回为"579" #PS:LeetCode415题就是要写这个函数 l1, l2 = len(s1), len(s2) if l1 < l2: s1, s2 = s2, s1 l1, l2 = l2, l1 s1 = [int(x) for x in s1] s2 = [int(x) for x in s2] s1, s2 = s1[::-1], s2[::-1] for i, digit in enumerate(s2): s1[i] += s2[i] s1 = self.CarrySolver(s1) s1 = s1[::-1] return "".join(str(x) for x in s1)复杂度分析
时间复杂度为 O(MN)O(MN),M 和 N 分别为 num1,num2 的长度空间复杂度为 O(M + N)O(M+N)
作者:JiayangWu
链接:https://leetcode-cn.com/problems/two-sum/solution/python-zi-fu-chuan-bao-li-mo-ni-shu-shi-cheng-fa-j/
来源:力扣(LeetCode)
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
class Solution:
def str2int(self,s):
return ord(s)-ord('0')
def multiply(self, num1: str, num2: str) -> str:
a = num1[::-1]
b = num2[::-1]
result = 0
for i,x in enumerate(a):
temp_result = 0
for j,y in enumerate(b):
temp_result += self.str2int(x) * self.str2int(y) * 10**j
result += temp_result * 10**i
return str(result)
5.翻转字符串里的单词
给定一个字符串,逐个翻转字符串中的每个单词。
示例 1:
输入: "the sky is blue"
输出: "blue is sky the"
示例 2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
示例 3:
输入: "a good example"
输出: "example good a"
解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
说明:
- 无空格字符构成一个单词。
- 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
- 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。
进阶:
请选用 C 语言的用户尝试使用 O(1) 额外空间复杂度的原地解法。
解答
- 先处理字符串,将首尾空格都删除;
- 倒序遍历字符串,当第一次遇到空格时,添加
s[i + 1: j](即添加一个完整单词); - 然后,将直至下一个单词中间的空格跳过,并记录下一个单词尾部
j; - 继续遍历,直至下一次遇到第一个空格,回到
1.步骤;
- 由于首部没有空格,因此最后需要将第一个单词加入,再return。
- python可一行实现。
class Solution:
def reverseWords(self, s: str) -> str:
s = s.strip()
res = ''
i ,j = len(s)-1,len(s)
while i > 0:
if s[i] == ' ':
res += s[i+1:j]+' '
while s[i] == ' ':
i -= 1
j = i+1
i -= 1
return res+s[:j]
Python strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
6.简化路径
以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。
在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。更多信息请参阅:Linux / Unix中的绝对路径 vs 相对路径
请注意,返回的规范路径必须始终以斜杠 / 开头,并且两个目录名之间必须只有一个斜杠 /。最后一个目录名(如果存在)不能以 / 结尾。此外,规范路径必须是表示绝对路径的最短字符串。
示例 1:
输入:"/home/"
输出:"/home"
解释:注意,最后一个目录名后面没有斜杠。
示例 2:
输入:"/../"
输出:"/"
解释:从根目录向上一级是不可行的,因为根是你可以到达的最高级。
示例 3:
输入:"/home//foo/"
输出:"/home/foo"
解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。
示例 4:
输入:"/a/./b/../../c/"
输出:"/c"
示例 5:
输入:"/a/../../b/../c//.//"
输出:"/c"
示例 6:
输入:"/a//b////c/d//././/.."
输出:"/a/b/c"
解答
栈解决,把当前目录压入栈中,遇到..弹出栈顶,最后返回栈中元素。
class Solution:
def simplifyPath(self, path: str) -> str:
stack = []
path = path.split('/')
for item in path:
if item == '..':
if stack:
stack.pop()
elif item and item != '.':
stack.append(item)
return '/'+'/'.join(stack)
7.复原IP地址
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
示例:
输入: "25525511135"
输出: ["255.255.11.135", "255.255.111.35"]
解答
我们要知道IP的格式,每位是在0~255之间,
注意: 不能出现以0开头的两位以上数字,比如012,08…
思路一:暴力法
我们把所有出现可能都列举出来,看是否满足条件.
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
n = len(s)
res = []
def helper(tmp):
if not tmp or (tmp[0] == '0' and len(tmp) > 1) or int(tmp) > 255:
return False
return True
for i in range(3):
for j in range(i+1,i+4):
for k in range(j+1,j+4):
if i < n and j < n and k < n:
tmp1 = s[:i+1]
tmp2 = s[i+1:j+1]
tmp3 = s[j+1:k+1]
tmp4 = s[k+1:]
if all(map(helper,[tmp1,tmp2,tmp3,tmp4])):
res.append(tmp1+'.'+tmp2+'.'+tmp3+'.'+tmp4)
return res
思路二:回溯算法
class Solution:
def restoreIpAddresses(self, s: str) -> List[str]:
res = []
n = len(s)
def backtrack(i, tmp, flag):
if i == n and flag == 0:
res.append(tmp[:-1])
return
if flag < 0:
return
for j in range(i, i + 3):
if j < n:
if i == j and s[j] == "0":
backtrack(j + 1, tmp + s[j] + ".", flag - 1)
break
if 0 < int(s[i:j + 1]) <= 255:
backtrack(j + 1, tmp + s[i:j + 1] + ".", flag - 1)
backtrack(0, "", 4)
return res

发表回复